What We Built
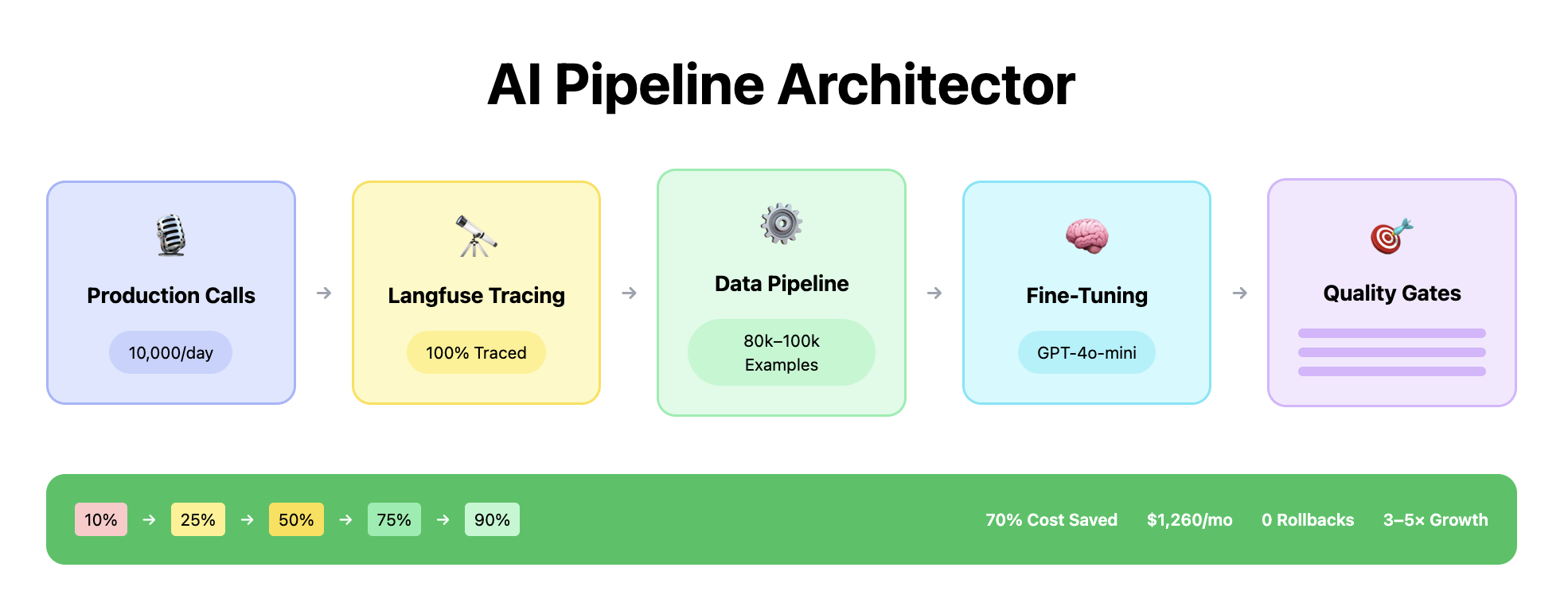
Prodinit designed and delivered a complete model distillation system over 10 weeks: Langfuse observability for data collection, a data cleaning and JSONL preparation pipeline, a semi-automated fine-tuning loop on Azure OpenAI, and a progressive A/B testing framework with evals at every rollout stage.
Observability and Data Collection
The first phase — weeks 0–2 — was instrumenting the client's voice AI stack with Langfuse. Prodinit integrated Langfuse to capture every production call: inputs, outputs, latency, and model metadata. This created the data flywheel that powers the entire distillation pipeline.
Langfuse serves two roles in the production system: retrospective data collection for training runs, and live observability for the A/B framework — tracking quality scores, hallucination rates, and latency deltas between GPT-4.1 and the fine-tuned GPT-4o-mini student model in real time.
Data Cleaning and JSONL Pipeline
Raw production calls are not training-ready. Prodinit built a data cleaning and filtering pipeline that:
- Filters low-quality examples — removes calls with incomplete turns, truncated responses, or flagged hallucinations
- Normalises prompt/completion pairs into the JSONL format required by Azure OpenAI fine-tuning
- Deduplicates near-identical examples to prevent overfitting on repeated patterns
- Targets 80,000–100,000 examples per training run — large enough for the student model to generalise across the client's full call domain
The pipeline is designed to run on a quarterly cycle, continuously improving the student model as new production data accumulates.
Fine-Tuning Pipeline on Azure OpenAI
Prodinit built a semi-automated fine-tuning pipeline on top of Azure OpenAI's fine-tuning API. The pipeline handles job submission, status polling, model registration, and eval triggering without manual intervention between stages.
GPT-4.1 acts as the teacher model: its production outputs are the training labels. The student model — GPT-4o-mini — is fine-tuned on these teacher-generated examples until it matches GPT-4.1 quality scores within the defined evals thresholds.
A/B Testing and Progressive Rollout Framework
The rollout framework was designed to eliminate the risk of a hard inference cutover at production scale. Traffic is split between GPT-4.1 (control) and the fine-tuned GPT-4o-mini (treatment) using a progressive allocation schedule:
10% → 25% → 50% → 75% → 90%
Each stage gate requires the student model to pass three eval criteria before the next increment is approved:
- Hallucination detection — automated checks against known ground-truth responses
- Quality scoring — conversation quality measured against GPT-4.1 baseline
- Latency tracking — p50 and p95 latency must remain within acceptable bounds
The final production configuration is a 90/10 hybrid: 90% of traffic served by fine-tuned GPT-4o-mini, 10% retained on GPT-4.1 as a quality floor. Langfuse provides live dashboards for both tracks.
Inference Cost: Before and After
The cost delta between GPT-4.1 and fine-tuned GPT-4o-mini is large. Based on Azure OpenAI pricing, a typical voice AI turn — roughly 1,000 input tokens and 500 output tokens — costs approximately:
| Model | Cost per call | Monthly at 10k calls/day |
|---|---|---|
| GPT-4.1 (before) | ~$0.006 | ~$1,800 |
| 90/10 Hybrid (after) | ~$0.0018 | ~$540 |
| Saving | ~$0.0042 | ~$1,260/month |
Figures are indicative based on Azure OpenAI published rates and typical token usage for the voice AI call domain. Actual numbers depend on average conversation length and token distribution.
The compounding effect is significant at scale: at 3x current volume (30,000 calls/day), the monthly saving grows proportionally — the distillation investment amortises quickly across growth.
Continuous Improvement
The pipeline is not a one-time exercise. Prodinit designed it around a quarterly retraining cycle that compounds quality gains over time:
- Collect — Langfuse accumulates a new production dataset each quarter. As call volume grows, each dataset is larger and more diverse than the last.
- Filter — the data cleaning pipeline removes degraded examples. Over time, this filter becomes more precise as evaluation criteria are refined from observed failure modes.
- Retrain — the fine-tuning job runs on the latest 80k–100k examples. Each run produces a student model that is better calibrated to current call patterns than the previous version.
- Evaluate — the evals framework compares the new student model against the current production student (not the teacher) — the quality bar rises each cycle.
- Promote — if evals pass, the new student model replaces the previous one via the same progressive rollout framework.
The result is a student model that improves every quarter on Prodinit's infrastructure, without requiring the client to manage training runs, evals, or deployment orchestration.
Results
Prodinit delivered the full 10-week engagement on schedule: distillation pipeline live, fine-tuned student model deployed, progressive rollout complete, and quarterly improvement cycle operational.
- 70% reduction in AI inference costs — per-call cost drops from ~$0.006 (GPT-4.1) to ~$0.0018 (90/10 hybrid), saving ~$1,260/month at 10,000 calls/day without quality regression in production evals
- 10,000+ calls/day handled at the new cost structure, with infrastructure designed for 3–5x growth before the next capacity constraint
- 80,000–100,000 training examples per distillation run — cleaned, filtered, and JSONL-formatted from production Langfuse data
- Progressive rollout completed across 5 stages (10% → 90%) with zero rollbacks — all stage gates passed on first attempt
- Quarterly continuous improvement cycle operational — each run further reduces the quality gap between student and teacher as more production data accumulates
- Langfuse observability live across 100% of production calls — hallucination rates, quality scores, and latency tracked per model, per call, per stage