What We Built
Prodinit redesigned the platform in five parallel workstreams over 12 weeks: a fully self-hosted LiveKit voice AI stack, Django infrastructure modernisation, database and Celery optimisation, ECS autoscaling, and a CI/CD QA pipeline.
Self-Hosted LiveKit Voice AI Stack
The centrepiece of the engagement was migrating voice AI off the Django WebSocket server entirely. Prodinit built and deployed a self-hosted LiveKit stack: the LiveKit server for WebRTC signalling and media routing, standalone Python agent workers (livekit_agents/) implementing a factory pattern for configurable AI pipeline selection, and LiveKit Egress for call recording directly to S3 — all running on Cuebo's own ECS infrastructure.
Self-hosting the full stack removes every LiveKit Cloud tier constraint: no limits on concurrent agent sessions, agent deployments, or egress minutes. The only scaling ceiling is ECS CPU and memory, both of which Prodinit configured to autoscale based on active connection count.
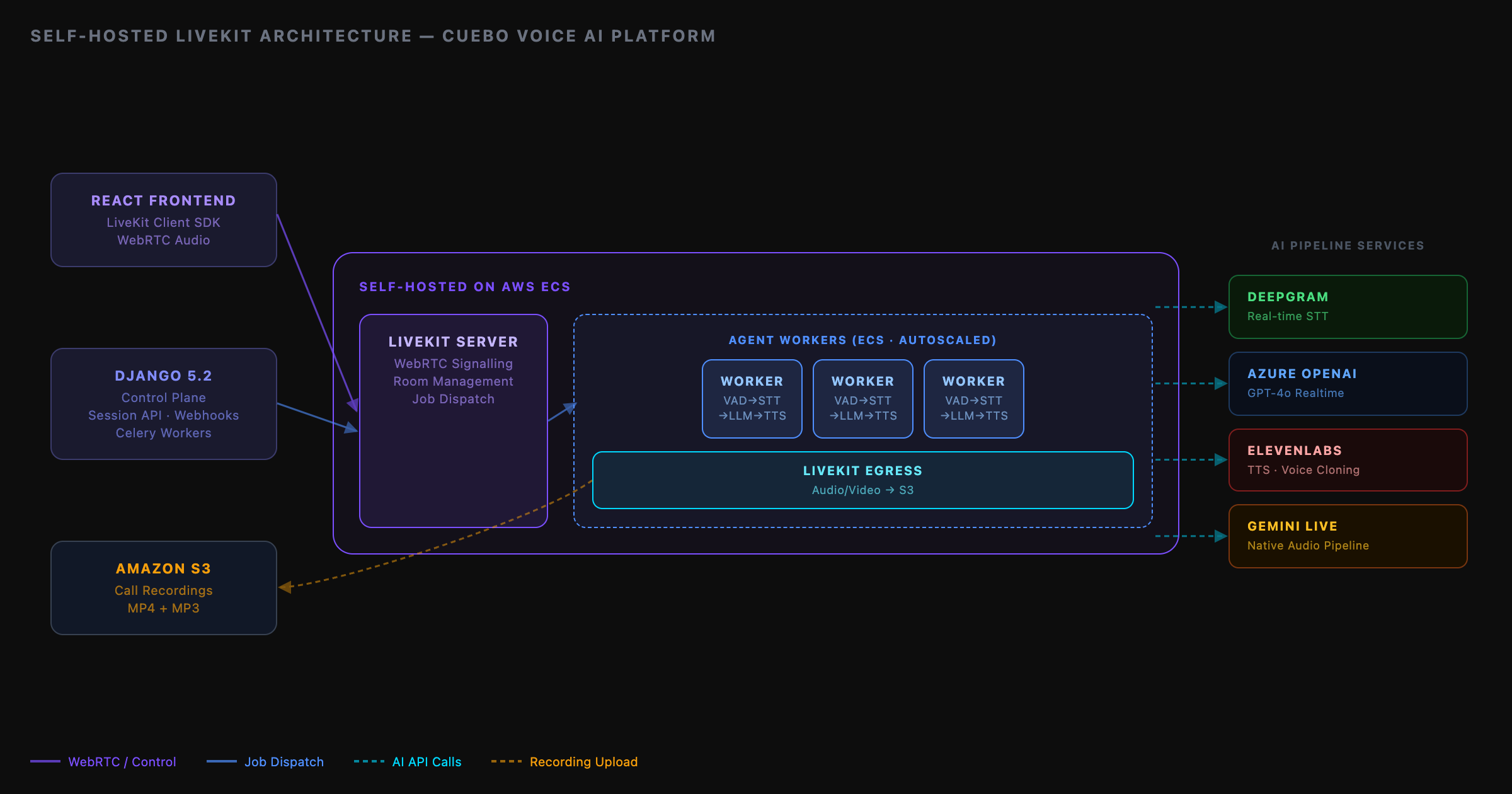
Each pipeline runs a VAD → STT → LLM → TTS chain with stopword detection, max-duration enforcement, and reconnect timeout monitoring. On call end, a background thread handles post-call work: MP4 assembly via imageio-ffmpeg at 15fps, S3 upload, transcript POST, and cleanup POST back to Django.
Django Control Plane and Infrastructure
Django was upgraded to version 5.2 and refactored into a clean control plane for LiveKit operations: LiveKitService for all API calls (room creation, JWT token generation, agent dispatch, egress management), REST endpoints for session lifecycle, webhook handling for participant_joined and room_finished events, and Celery tasks for stuck-call cleanup and health monitoring.
The frontend was migrated to AWS Amplify with automated deployments from Git, and WebSocket and API servers were separated into independently scalable services.
Sentry for application error tracking and PostHog for product analytics were integrated in week 1.
Performance Profiling and Database Optimisation
Prodinit deployed django-silk for SQL query profiling and Flower for Celery task monitoring across the development environment. Every API endpoint and background task was profiled; all queries exceeding 100ms were flagged and all queries exceeding 500ms were eliminated through targeted index additions and ORM refactoring.
Celery workers were reorganised into dedicated pools by task type: voice AI processing tasks routed to high-memory workers, notification tasks to I/O-optimised workers, and data processing tasks to CPU-optimised workers — with exponential backoff on transient failures.
ECS Autoscaling
Custom autoscaling policies were configured across three service tiers:
- API server — scale-up on CPU, memory, request count, and response time; minimum 2 tasks always running
- WebSocket server — scale-up on active connections and connection establishment rate; gradual scale-down
- Celery workers — scale on queue depth, task wait time, and worker CPU
- Scheduled scaling — pre-scale 15 minutes before known peak hours; separate weekend and weekday profiles
Results
Prodinit delivered the full 12-week engagement on schedule: self-hosted LiveKit voice AI stack live with 5 configurable AI pipelines, infrastructure capable of handling 10x peak load, all slow database queries eliminated, and the Django control plane fully decoupled from voice AI processing.
- 10x peak load capacity — multi-metric ECS autoscaling handles traffic spikes without proportional cost increase
- 0 concurrent session limits — self-hosted LiveKit server, agent workers, and egress remove all LiveKit Cloud tier constraints entirely
- 5 AI pipeline variants deployed and selectable per session — Deepgram STT, Azure OpenAI GPT-4o Realtime, ElevenLabs TTS, Azure Speech, Claude Sonnet, Sarvam, Google Gemini Live, Google Chirp, and Gemini Chat all integrated via factory pattern dispatch
- 100% of database queries over 500ms eliminated after Silk profiling across all API endpoints and background tasks
- Frontend migrated to AWS Amplify with full CI/CD from Git; WebSocket and API servers independently scalable from week 3
- Celery task isolation across 3 dedicated worker pools (high-memory, I/O-optimised, CPU-optimised) with queue-depth autoscaling